












Chrome拡張機能を使ってダウンロードする方法を書きました!

独自スクリプトを利用してAvgleの動画をダウンロードする方法をご紹介します。
AvgleではHLS形式(m3u8+ts)の動画ストリーミングを採用しており、Video DownloadHelperなどでは簡単に保存ができません。
以前はffmpegを利用してm3u8からtsを保存する方法がありましたが、現在ではそれは利用できないとのことです。私が確認したところPythonを使えば保存可能であることが判明したので、m3u8ファイルから動画(tsファイル)のURLを読み込み、Pythonで保存するスクリプト(Python)を書きました。
Windowsの方は下の記事を参照してください。

2018/09/07) 本スクリプトに基づいたGUIアプリ(Mac/Win対応)をリリースしました!
iPhoneでも簡単にダウンロードできます。詳しくはこちら。
2018/10/06) AndroidでのAvgleダウンロード方法も書きました。
注意! 著作権は遵守すること。本記事の方法を試す際は自己責任でお願いします。
準備
- Chrome
- 動画ゲッター(Link)
- Python(標準のPythonでOK)
* 動作確認はMacでのみ行ってます。
m3u8をダウンロード
まず、動画のm3u8ファイルをダウンロードします。m3u8ファイルをダウンロードするにはChromeの拡張機能である「動画ゲッター(Link)」を用いるのが簡単なのでインストールしておきましょう。
実際に動画ページで動画ゲッターのボタンを押すと下図のようにm3u8をダウンロードできます。
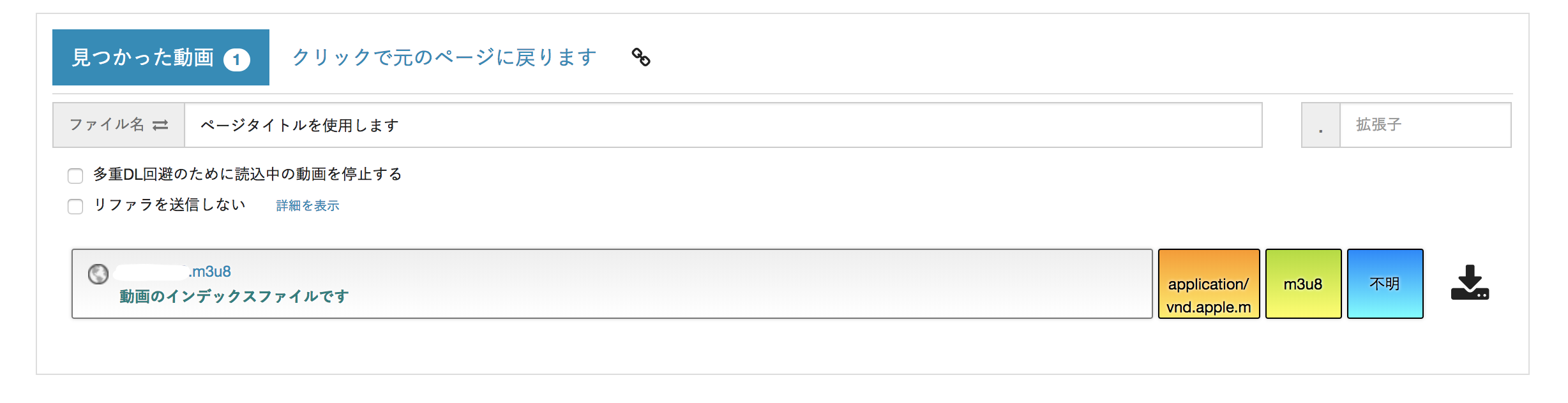
Pythonスクリプトを使って動画を保存
スクリプト作成
次のスクリプトをコピーし、テキストエディットなどに貼り付けて適当なディレクトリに.py形式でファイルを保存してください(例:m3u8.py)。環境によっては動かない場合もあります。
2018/08/31 追記)簡単のためm3u8.pyをアップロードしました→ダウンロードはこちら。
import argparse
import os
import re
try: #python3
import urllib.request as urllib
except: #python2
import urllib2 as urllib
import subprocess
# cmd arg
parser = argparse.ArgumentParser()
parser.add_argument("path",
help="m3u8 file path",
type=str, default=None)
parser.add_argument("-o",
help="Output dir",
type=str, default="~/Downloads")
args = parser.parse_args()
# make save dir
file_name = args.path.split('/')[-1].replace('.m3u8', '')
dir = os.path.expanduser(args.o + "/" + file_name)
if not os.path.exists(dir):
os.makedirs(dir)
# load m3u8
opener = urllib.build_opener()
with open(args.path) as f:
os.chdir(dir)
i = 0
authority = ""
for line in f:
if 'https://' in line:
line = line.rstrip()
print("Downloading of " + line)
if authority == "":
res = re.search('https:\/\/(.*?)\/', line)
authority = res.group(1)
opener.addheaders = {
("Origin", "https://avgle.com"),
("Accept-Encoding", "gzip, deflate, br"),
("Accept-Language", "ja,en-US;q=0.9,en;q=0.8"),
("Accept", "*/*"),
("Referer", "https://avgle.com/video/"),
("Connection", "keep-alive")
}
urllib.install_opener(opener)
with open("{:0>10}_out.ts".format(str(i)), 'wb') as f:
f.write(urllib.urlopen(line).read())
i += 1
# merge ts files
subprocess.call('cat *_out.ts > "{}.ts"'.format(file_name), shell=True)
subprocess.call('rm *_out.ts', shell=True)
スクリプトの実行
次にTerminalで上記スクリプトを実行します。下記の例のようにコマンドを実行すればm3u8ファイルが読み込まれ動画のダウンロードが開始されます。デフォルトでは保存先は「/Users/[ユーザー名]/Downloads」です。
例:
python m3u8.py hogehoge.m3u8

一つ一つのtsファイルが順次ダウンロードされるため長時間の動画ですとかなりの時間がかかります。
なお、動画の保存先を変更する場合は-o引数で保存先のパス(できれば絶対パスで)を指定してください。
例:
python m3u8.py hogehoge.m3u8 -o /Users/[ユーザー名]/Videos
Pythonスクリプトの説明
m3u8ファイルに記述されているtsファイルのURLを取得し順次PythonでDLするスクリプトです。
最後にすべてのtsが保存されたらcatコマンドで一つのtsに結合し、いらなくなったファイルを削除する処理を行っています。
冗長な処理や稚拙なコードが存在しますので、適宜改変してご使用いただければと思います。
以上、お読みいただいきありがとうございました!
2018/10/18 追記) Python2で動かない問題を修正しました。


コメント
当方windowsユーザーなのですが、curlを導入してみて上のスクリプトを試してみたのですが、
上手く動作しませんでした。
windows用のスクリプトを書いていただけないでしょうか?
宜しくお願いします。
> 当方windowsユーザーなのですが、curlを導入してみて上のスクリプトを試してみたのですが、
> 上手く動作しませんでした。
>
> windows用のスクリプトを書いていただけないでしょうか?
> 宜しくお願いします。
閲覧いただきありがとうございます。
確かにWindowsのコマンドプロンプトだと動作しないと思います。
[打消]Windows Subsystem for Linuxを導入すればMacと同様に動作するように思います。[/打消]
当方Windows機を直ちに用意できないため後日また記事にしたいと思います。
よろしくお願いします。
2018/05/22 追記)下記にWin対応版を公開しました!
https://phexcel.work/blog-entry-459.html
昨日までこちらのスクリプトを使わせていただいていたのですが、今日になって突然ダウンロードされた ts ファイルが数 KB のファイルになってしまい、元の *.ts ファイル群を確認したところ 403 エラーページがダウンロードされているようでした。
この症状は私だけでしょうか?
大量のファイルをダウンロードしすぎて IP アドレスでブロックされていることも有り得るのでしょうか?
何か対策などあれば教えていただけると幸いです。
> 昨日までこちらのスクリプトを使わせていただいていたのですが、今日になって突然ダウンロードされた ts ファイルが数 KB のファイルになってしまい、元の *.ts ファイル群を確認したところ 403 エラーページがダウンロードされているようでした。
> この症状は私だけでしょうか?
> 大量のファイルをダウンロードしすぎて IP アドレスでブロックされていることも有り得るのでしょうか?
> 何か対策などあれば教えていただけると幸いです。
閲覧ありがとうございます。
私の環境でダウンロードを試みましたところ正常にダウンロードできていました。
403エラーが出る理由は不明ですが、curlのuser-agentを変更してみる、Refererを動画のURLに変更するといった対策が思い浮かびます。
たしかに、avgle側でブロックされているかも知れませんので少し時間をおいてみるのもしれません。
2018/05/22 追記)m3u8が古いと403が出るようです。新しくDLし直すと直るかもしれません。
SECRET: 1
このブログに書いてある通りに、テキストエディットにスクリプトをダウンロードフォルダーに[m3u8.py]で保存し、ターミナルで[python m3u8.py hogehoge.m3u8]のコマンドを入力したところ[: can’t open file ‘m3u8.py’: [Errno 2] No such file or directory] というエラーメッセージが出てしまいました。
恥ずかしながらコンピュータ初心者でどう解決したらいいか分かりません。誠に勝手ながらご教授願えないでしょうか。よろしくお願いします。
このブログに書かれている通り、m3u8のファイルをダウンロードし、テキストエディットに上記スクリプトをダウンロードフォルダに[m3u8.py]で保存した後、ターミナルで[python m3u8.py hogehoge.m3u8]のコマンドを入力、実行したところ[python: can’t open file ‘m3u8.py’: [Errno 2] No such file or directory]というエラーメッセージが表示されてしまいました。
恥ずかしながら、コンピュータ初心者でどう解決したらいいか分かりません。誠に勝手ながら、ご教示願いたいです。よろしくお願いします。
ターミナルのカレントディレクトリがおそらくホームディレクトリ(/Users/[ユーザー名])になっているためスクリプトを参照できないんだと思います。確実に動かすにはスクリプトの絶対パスを指定すれば良いと思います。
例えば「python /Users/[ユーザー名]/Downloads/m3u8.py [m3u8のパス]」のような感じです。
スクリプトファイルをターミナルにD&Dすればスクリプトの絶対パスを簡単に貼り付けできます。
他にはスクリプトをホームディレクトリに移動する、または、「cd ./Downloads」と入力してダウンロードフォルダをカレントディレクトリにするなどの方法が挙げられます。
ご参考になりましたら幸いです。
[斜体]斜体の文[/斜体
あなたが神か…
こちらのブログに書かれている通りに手順を進めましたが、
File "m3u8.py", line 1
SyntaxError: Non-ASCII character ‘\xff’ in file m3u8.py on line 2, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
と表示され、ダウンロード出来ません。
どこがおかしいのか教えていただけないでしょうか?
よろしくお願いいたします。
ご助言ください
File “m3u8.py”, line 34, in
authority = re.match(‘https:\/\/(.*?)\/’, line)[1]
TypeError: ‘_sre.SRE_Match’ object is not subscriptable
とでます。
ご指摘ありがとうございます。
環境によっては動作しない構文を書いてしまっていたようです。
修正したコードを上げましたのでそちらをお使いください。→こちら
感謝します。
以前までこちらの方法でダウンロードできていたのですが、先程ダウンロードすると以下のようなエラーが出力されます。
ダウンロードしてから時間が経過し過ぎているのかと思いダウンロードしてからすぐに実行してみたのですがやはりエラーが出力されます。
また、時間の経ちすぎているであろう古いファイルでも同様のエラーが出力されます。
403 Forbiddenというところから考えても、avgle側から対策されたのでしょうか。
確認よろしくお願いします。
———————————————————————————————————————-
Downloading of https://ip107321632.ahcdn.com/key=61YoqCPG0DT-Q-3thfv9yg,s=,end=1536284767,limit=2/data=1536284767/state=lkFt/reftag=56109644/media=hlsA/ssd2/177/3/56238893.mp4/seg-1-v1-a1.ts
Traceback (most recent call last):
File “m3u8.py”, line 46, in
urllib.request.urlretrieve(line, “{:0>10}_out.ts”.format(str(i)))
File “~/anaconda3/lib/python3.6/urllib/request.py”, line 248, in urlretrieve
with contextlib.closing(urlopen(url, data)) as fp:
File “~/anaconda3/lib/python3.6/urllib/request.py”, line 223, in urlopen
return opener.open(url, data, timeout)
File “~/anaconda3/lib/python3.6/urllib/request.py”, line 532, in open
response = meth(req, response)
File “~/anaconda3/lib/python3.6/urllib/request.py”, line 642, in http_response
‘http’, request, response, code, msg, hdrs)
File “~/anaconda3/lib/python3.6/urllib/request.py”, line 570, in error
return self._call_chain(*args)
File “~/anaconda3/lib/python3.6/urllib/request.py”, line 504, in _call_chain
result = func(*args)
File “~/anaconda3/lib/python3.6/urllib/request.py”, line 650, in http_error_default
raise HTTPError(req.full_url, code, msg, hdrs, fp)
urllib.error.HTTPError: HTTP Error 403: Forbidden
ご指摘ありがとうございます。確かに403エラーが出ていることが確認できましてソースコードを修正しました。
お手数ですが、古いスクリプトを削除していただき、新しい方をご利用ください。
以前使えていたのですが
新しいものに変えると
Traceback (most recent call last):
File “m3u8.py”, line 4, in
import urllib.request
ImportError: No module named request
というエラーが出てしまいました。
どうすればいいでしょうか?
すみません、Python2では動作しないバグがありました。
バグは修正しましたので動くようになったかと思います。
どうぞ、お確かめください。
https://1drv.ms/u/s!ApuoeF8K-m4PbMFRfKf2jApkZBE
管理人様
修正ありがとうございました。
試したところ
File “m3u8.py”, line 49, in
f.write(urllib.urlopen(line).read())
File “/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/urllib2.py”, line 154, in urlopen
return opener.open(url, data, timeout)
File “/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/urllib2.py”, line 437, in open
response = meth(req, response)
File “/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/urllib2.py”, line 550, in http_response
‘http’, request, response, code, msg, hdrs)
File “/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/urllib2.py”, line 475, in error
return self._call_chain(*args)
File “/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/urllib2.py”, line 409, in _call_chain
result = func(*args)
File “/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/urllib2.py”, line 558, in http_error_default
raise HTTPError(req.get_full_url(), code, msg, hdrs, fp)
urllib2.HTTPError: HTTP Error 403: Forbidden
というエラーが出てしまいました。
何度も申し訳ございません。
もしお手すきであれば、ご確認お願いいたします。
こちらの環境では動きましたので、おそらくm3u8ファイルが古い可能性があります。
m3u8が古いと403 Forbiddenエラーが発生します。
もう一度m3u8をダウンロードし直してみて試していただけますか。
すばらしいです!ありがとうございます。
2019.1.19頃から動画ゲッターで検出出来なくなってますね。Avgle側が対策したかな?
対策したかも
いつの頃からか、また元の方式に戻ってますね。なのでまたこのスクリプト使わせて頂いてます。
raise HTTPError(req.full_url, code, msg, hdrs, fp)
urllib.error.HTTPError: HTTP Error 403: Forbidden
と出ますね。15秒前にダウンロードしたm3u8です。